很多面试官早就对“Redis缓存、MySQL分库分表”这些东西形成免疫了,他们更想要听到的是一个完整的链路,比如从服务到数据、从接入到落地的全流程设计。
当时面试官问我:
一家电商公司,它主要是面向消费者的,公司的一些业务场景流量会很高,比如说展示商品的那个页面,它的流量就很高,假设现在由你来做这个系统,负责商品详情页的展示,你能从服务的层面,数据的层面等多个维度来设计一下,让它能够支持一个更高的查询能力。
场景梳理
业务背景
电商商品详情页,面对百万级QPS的高并发流量(比如大促、爆款商品)。
需求分析
- 性能:支持高并发查询,响应时间 < 100ms
- 一致性:商品价格、库存、标题修改后,能及时更新
- 高可用:服务挂了、Redis挂了,系统不崩
- 可扩展:新增商品、新增规格,能快速接入
关键数据
商品基本信息(标题、主图、详情图)、价格(实时/活动)、库存、规格参数、促销信息(优惠券/秒杀)、评价统计。
设计思路
以“多级缓存”为核心,配合“服务分层+数据分层+异步更新”,构建“读多写少”的高并发详情页系统。
系统架构
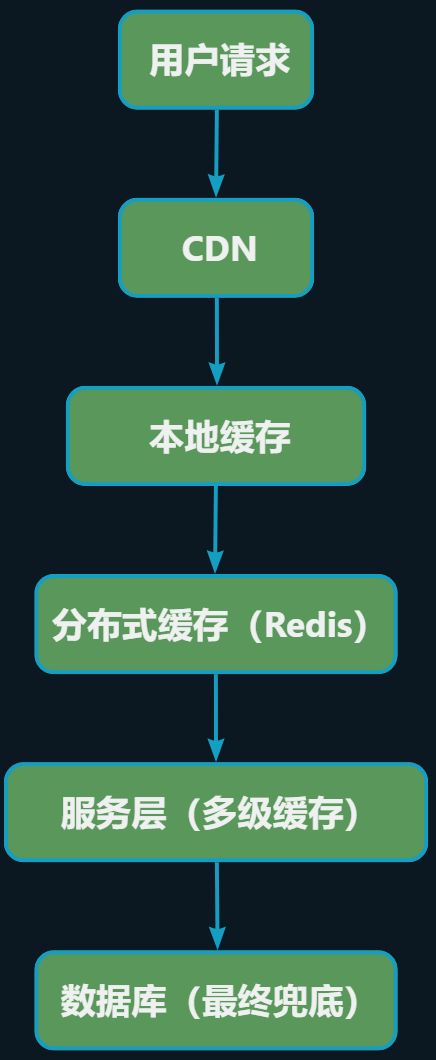
服务层面
采用前后端分离+网关层+服务分层架构:
| 层级 | 作用 |
|---|---|
| CDN层 | 静态资源加速(图片、js、css、详情页HTML) |
| 网关层 | 路由、限流、鉴权、接口聚合 |
| API网关聚合层 | 聚合多个微服务接口(比如商品基础信息、价格、库存、评价),减少请求次数 |
| 商品服务层 | 核心业务逻辑(查商品、查库存、查价格) |
| 数据服务层 | 专门做数据查询(缓存+数据库) |
商品详情页是典型的读多写少场景,考虑服务层本地缓存 + 分布式缓存。
采用Caffeine作为服务层本地缓存,缓存极热点商品(比如爆款商品),避免每次请求都走Redis,
采用Redis作为分布式缓存,作为核心缓存层,缓存所有商品的详情数据。
调用流程:
先查本地缓存(Caffeine),如果命中就直接返回;
如果本地未命中,查 Redis,命中则写入本地缓存,返回;
如果Redis 未命中,查数据库,查到则写入 Redis + 本地缓存,返回。
数据层面
商品数据分为3类,不同类型用不同策略:
| 数据类型 | 例子 | 缓存策略 |
|---|---|---|
| 静态数据 | 商品标题、主图、详情图、规格参数 | 永久缓存(不过期),更新时主动删除 |
| 半动态数据 | 商品价格、促销信息(优惠券、满减) | 短期缓存(5-10分钟),更新时主动删除 |
| 动态数据 | 库存(实时)、实时销量 | 单独缓存,库存用Redis原子操作;实时销量异步更新 |
缓存更新的原则:
为了避免高并发下的缓存不一致问题,采用的是先更新数据库,再删除缓存的方式。
高并发优化
1.热点数据预热
大促前,把热门商品(如销量TOP100)写入Redis和本地缓存。
- 限流+熔断+降级
对商品详情接口设置限流。
考虑使用服务熔断,当Redis/数据库不可用时,快速失败,避免系统雪崩。
或者考虑使用降级策略,当Redis挂了,降级到直接查数据库,如果数据库也挂了,降级返回默认商品信息。
- 页面静态化
对于完全静态的商品(比如虚拟商品或者不参与促销的商品),生成静态HTML页面,直接存到CDN,这样的话用户请求直接由CDN返回,不经过任何服务。